
当我还在感叹 Github Copilot 辅助写代码有多方便的时候、思考普通人能用 GPT 做什么事的时候,AI 就已经突然发展到了一个我看不懂的地步,突然冒出了诸如 Agent、RAG、MCP 这类陌生的名词。本篇文章梳理一下这些名词究竟是什么。
大语言模型(LLM)
大语言模型是一种深度学习模型,它的训练集是海量的文本数据,使得它可以执行各种自然语言处理任务,例如文本翻译、问答。OpenAI 发布的 GPT-3 ,第一次使的 LLM 进入了公众视野(其实是 ChatGPT 这个软件被大家熟知了)。
LLM 的工作原理是通过自监督学习,从互联网规模的数据集中学习语言模式。然而,它们的局限性在于依赖静态训练数据,可能生成过时或不准确的信息。例如,LLM 可能“幻觉”出不存在的事实,因为它们仅基于统计关系理解语言,而非实际意义。
DeepSeek R1/V3,GPT3/4o 这些都是 LLM
Agent
一种利用 LLM 自主执行任务或与用户互动来实现预定目标的程序。简单来讲就是,Agent 就是给 LLM 加上了手,让这个程序不只是能完成问答对话,能够输出一些我们想要的东西。
对于目前常用的 AI 开发工具 Cursor 来说,Agent 模式下会将你的指令拆解为各个任务,检索上下文,针对不同任务调用不同的工具去完成最终的输出。
当 LLM 输出代码后,Agent 会调用工具(API)检测是否存在错误(IDE 本身的报错),存在错误就会将错误信息反馈给 LLM,重新进行代码调整。
在这个过程中,LLM 做的工作是:理解需求、通过思考链将用户需求分解为各个任务、将项目文件作为知识库关联到上下文中、语义分析后决定下一步调用哪个工具执行任务。也就是说 LLM 将各个工具(API)连接了起来,形成了 Agent。
检索增强生成(RAG)
检索增强生成(RAG)是一种优化 LLM 性能的框架,通过在生成响应前从外部知识库检索事实,确保输出基于你提供的信息。RAG 的核心是结合信息检索和文本生成,解决 LLM 依赖静态训练数据的局限。
用户提出问题或任务 → 系统从知识库(如数据库或上传文档)中检索相关信息 → 检索到的信息作为上下文提供给 LLM → LLM 生成基于这些信息的响应
模型上下文协议(MCP)
一个针对 LLM 的技术协议,能够让 LLM 与外部数据源建立连接。
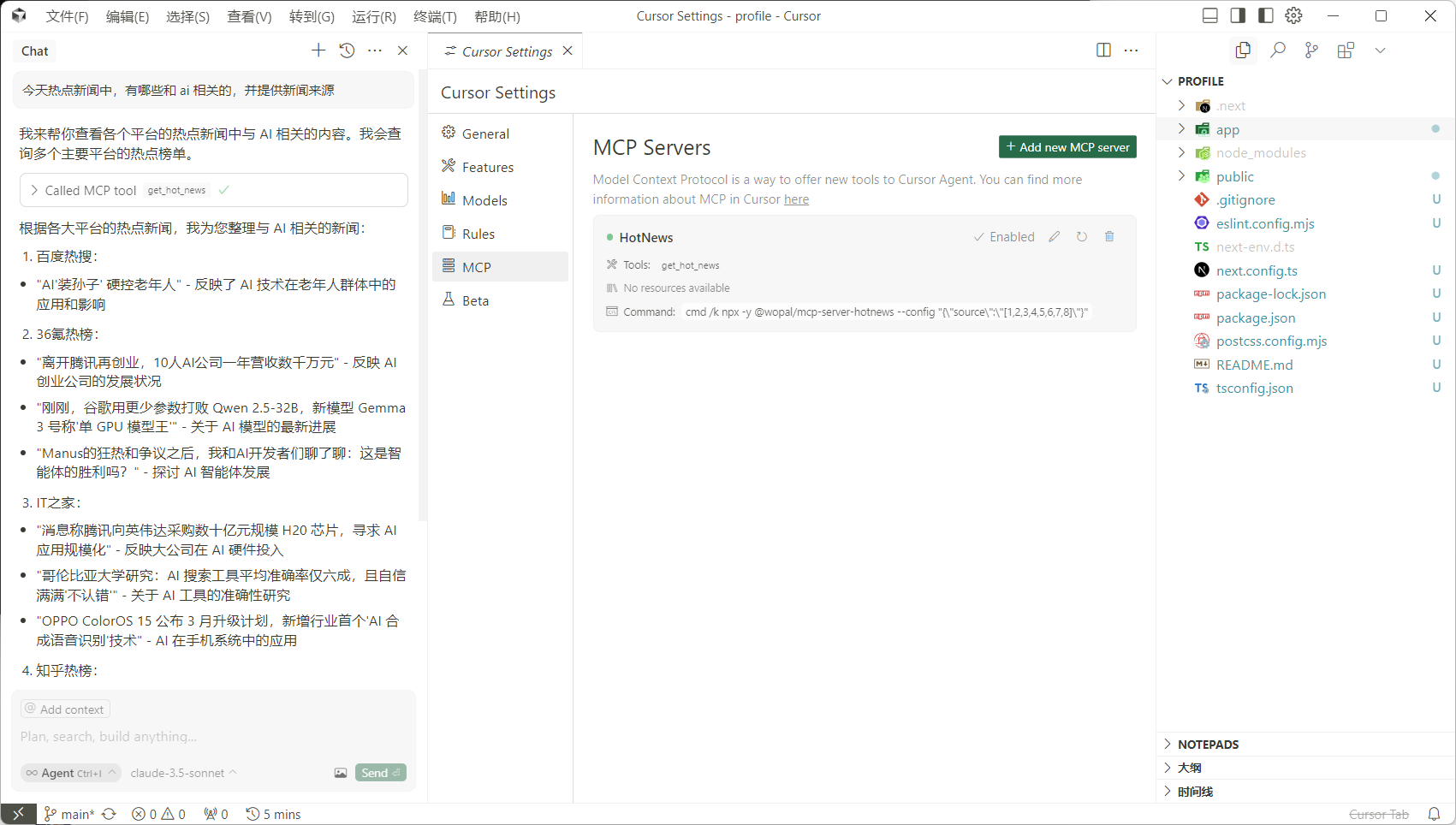
同样还是 Cursor,如果我想在写代码的时候偶尔摸一下鱼,可以给 Cursor 添加一个今日热榜的 MCP 服务(分为 SSE 和 本地跑命令 两种模式),这样 Cursor 就可以轻松的告诉你当前热点信息。当然这种功能通过编辑器的插件也能实现,关键在于这个 MCP 可以扩展 LLM 能力边界,将自然语言转换为工具链的调用(比如直接读取数据库文件,通过自然语言拿到你想要的数据进行数据分析)。
文章地址: https://blog.qiyuor2.me/2025/ai_agent_what
本作品由 柒宇 采用 CC BY-NC-SA 4.0 进行许可,转载请注明出处。